
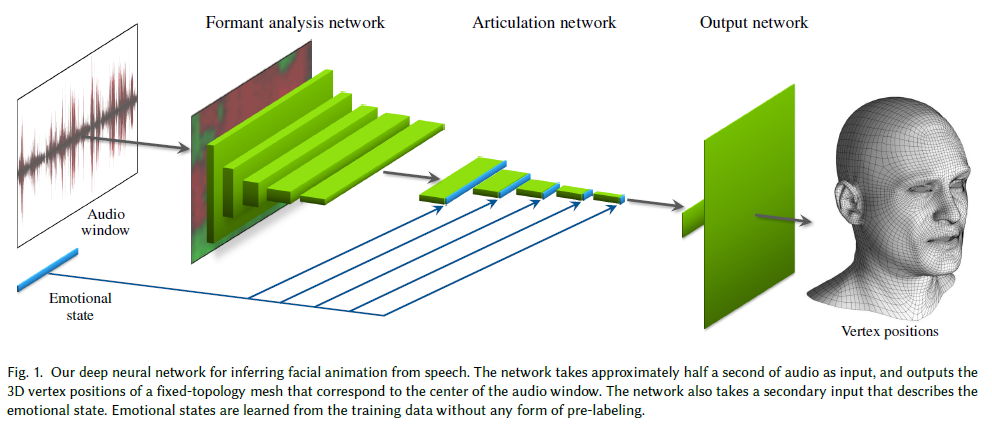
Tero Karras, Timo Aila, Samuli Laine, Antti Herva (Remedy Entertainment) et Jaakko Lehtinen (NVIDIA and Aalto University) ont présenté cet été au SIGGRAPH un travail de recherche sur l’animation automatisée d’un visage à partir de l’enregistrement sonore de la voix d’une personne.
La publication, intitulée Audio-Driven Facial Animation by Joint End-to-End Learning of Pose and Emotion, propose une méthode qui s’appuie sur le machine learning. L’apprentissage par le réseau de neurones se fait via 3 à 5 minutes d’animation de qualité obtenue par exemple par des méthode de performance capture (à l’aide de caméras).
Les chercheurs soulignent que leur technique vise à se concentrer sur une personne à la fois (le système apprend à partir de la voix et des expressions d’un acteur précis), mais qu’en pratique les résultats sont relativement acceptables même si on utilise sur le système l’enregistrement audio d’une autre personne. Y compris si la langue, l’accent ou le genre diffèrent de ceux du modèle de départ.
Les applications de ce type de recherche sont larges, précisent les auteurs : dialogues dans le jeu vidéo, localisation à faible coût, avatars en réalité virtuelle ou encore téléprésence.
Voici également une comparaison des résultats de trois publications présentées au SIGGRAPH dans la session Speech & Facial Animation.